facet_wrap(): nel caso in cui si voglia usare una sola variabile categorica e decidere il numero di pannelli per ogni riga/colonna
facet_grid(): nel caso in cui le variabili categoriche fossero due o in casi particolari di una sola variabile
NB: ho parlato di sole variabili categoriche, perchè nel caso di variabili continue si avrebbe un pannello per ogni valore della variabile continua utilizzata; il risultato sarebbe un insieme di grafici veramente poco chiaro.
Facet_wrap
Questa funzione è utile quando si vogliono creare più pannelli in base ad una variabile categorica.
Vediamone subito come usarla: il comando è facet_wrap( ~ categorica).
ggplot(data = mtcars) +
geom_point(mapping = aes(x = mpg, y = hp), color = "blue") +
facet_wrap(~ cyl)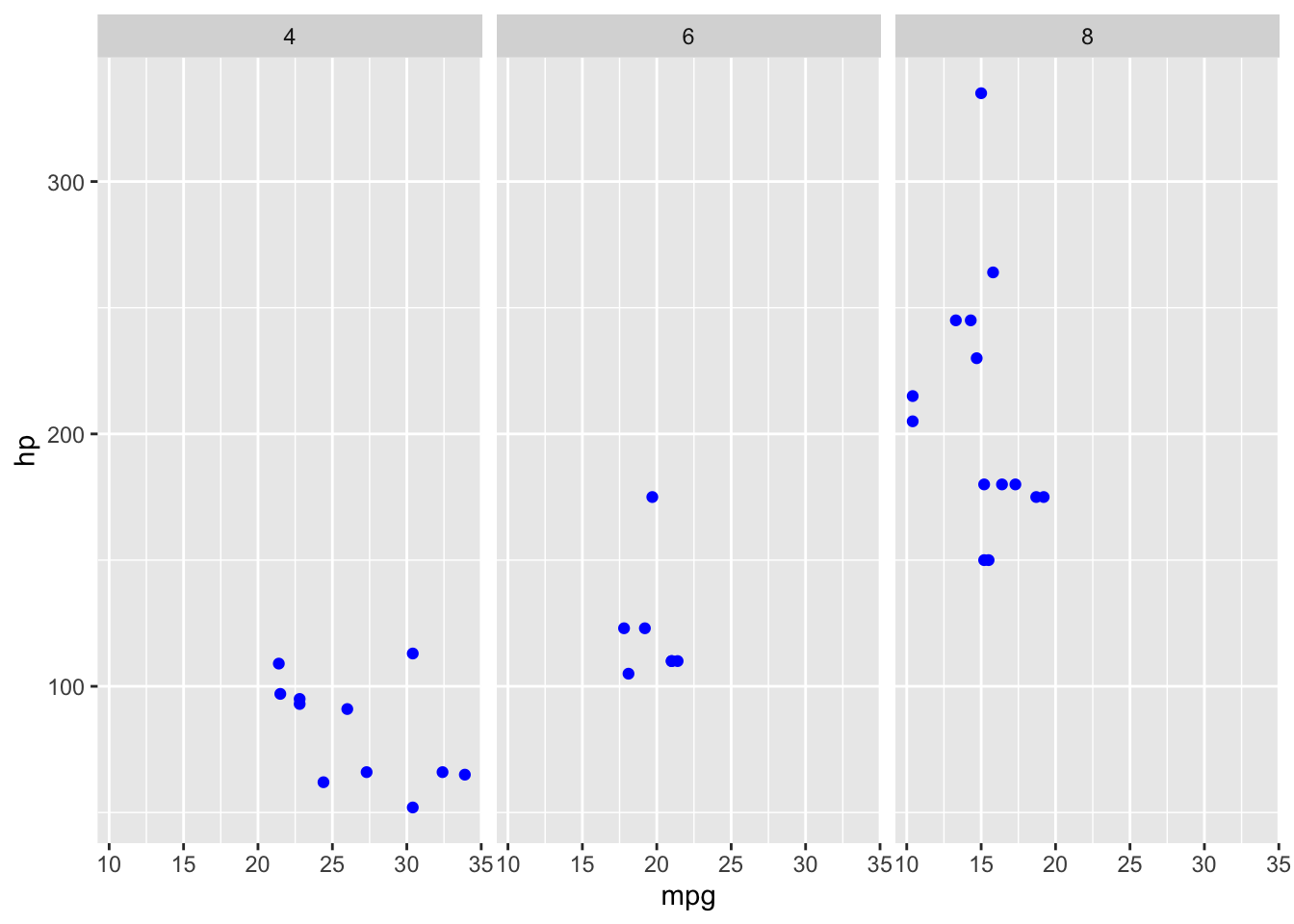
Figura 1: Esempio dell’uso di facet_wrap
Come si può vedere, la funzione ha suddiviso lo scatter plot in 3 scatter plot, uno per ogni categoria di cyl (4, 6 e 8). In questo modo si evita il fenomeno chiamato ‘overplotting’, che si ha quando ci sono troppi punti plottati e diventa difficile distinguerli.
Vediamo ora quali altri input si possono dare alla funzione:nrow o ncol: difiniamo il numero di righe o colonne. Utile quando si hanno tanti pannelli per organizzarli in griglia piuttosto che averli tutti schiacciati o in orizzontale o in verticaledir: le opzioni sono ‘h’ o ‘v’, per definire l’orientamento verticale o orizzontale della suddivisione. In pratica, decidiamo se avere i grafici suddivisi per colonna, come nell’esempio, o per riga
drop: opzione importante se si vogliono eliminare i grafici corrispondenti alle categorie senza alcun dato (grafici vuoti). Le opzioni sono T (elimina) o F (mantieni tutti)strip.position: indichiamo la posizione delle etichette della variabile categorica con le parole top, bottom, left o right
ggplot(data = mtcars) +
geom_point(mapping = aes(x = mpg, y = hp), color = "blue") +
facet_wrap(~ cyl, dir = "v", strip.position = "right")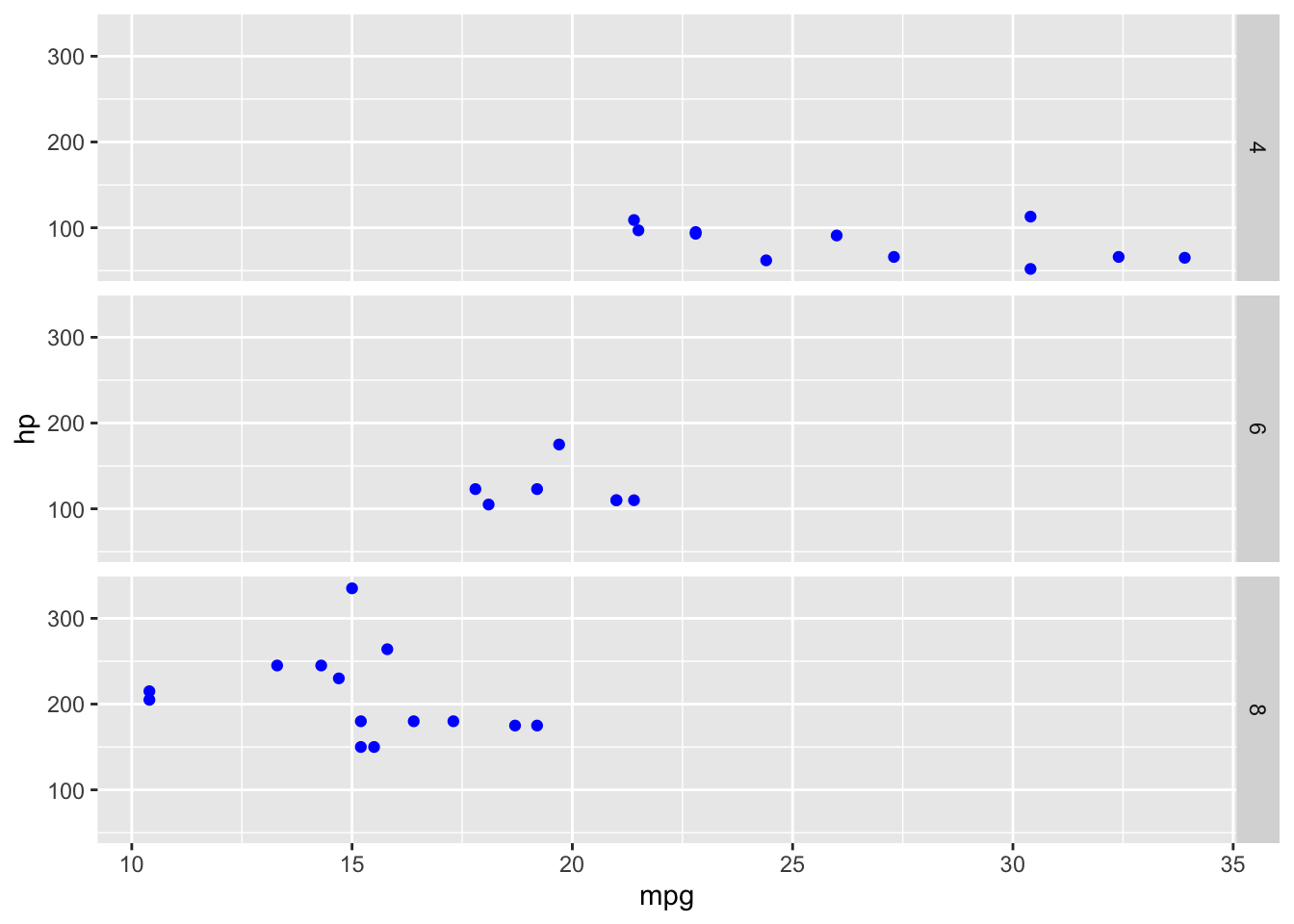
Figura 2: Esempio di grafico suddiviso per riga e con le etichette della variabile categorica a destra
Tra le opzioni di sopra non ne ho citata una molto importante, perchè vorrei analizzarla più nel dettaglio ora.
Questa opzione è chiamata scales e ci permette di decidere se gli assi saranno uguali tra i vari pannelli oppure saranno ‘liberi’, ovvero se in ogni pannello gli assi avranno range diversi in base ai dati che conterrà. Le opzioni sono: fixed (uguali in tutti), free (ogni dimensione è libera), free_x/y (solo una dimensione è libera).
Vediamo subito un esempio, lasciando libero l’asse x della figura 1.
ggplot(data = mtcars) +
geom_point(mapping = aes(x = mpg, y = hp), color = "blue") +
facet_wrap(~ cyl, scales = "free_x")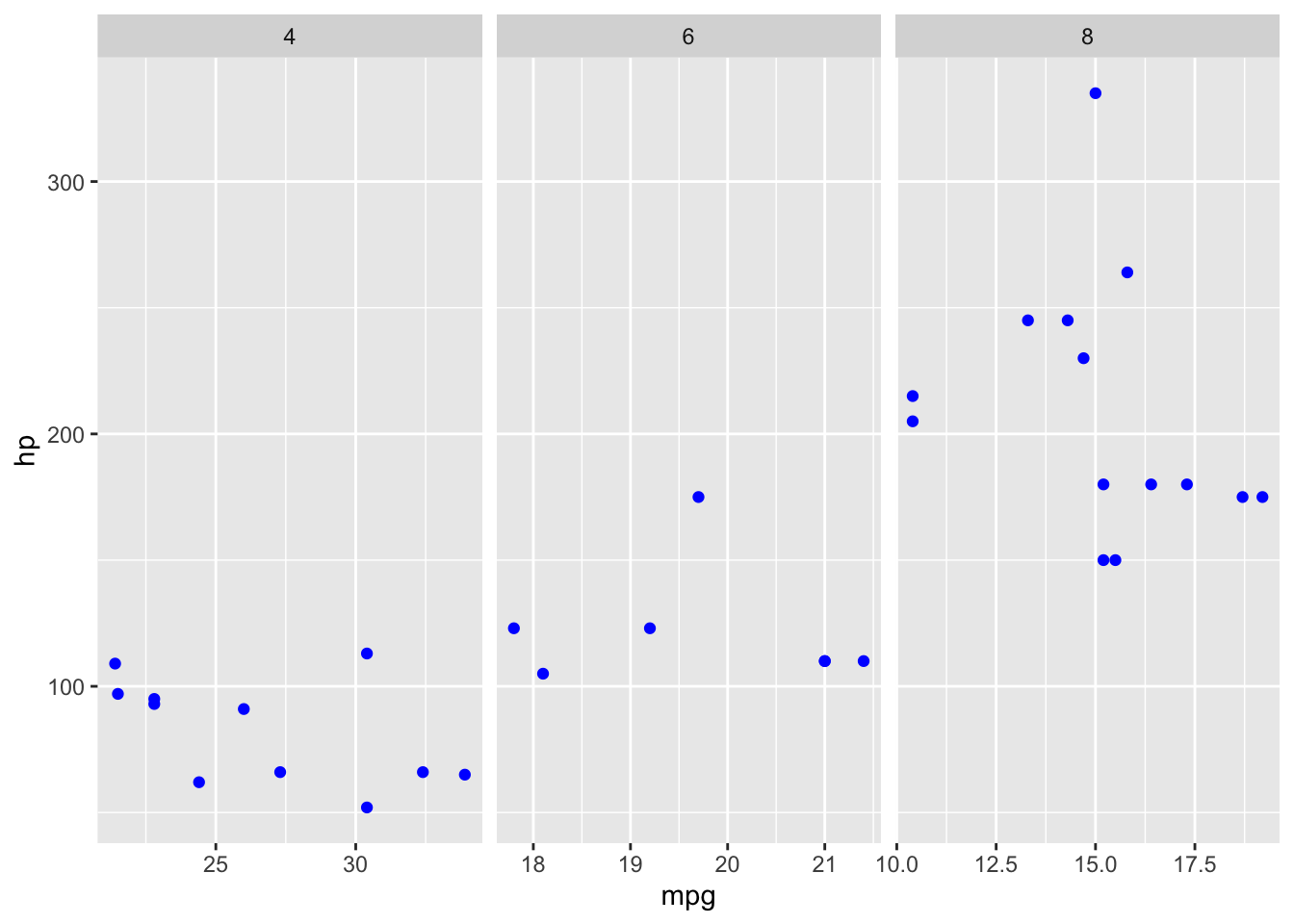
Figura 3: Esempio di scales libero sull’asse x
In questo modo i vari pannelli sono più “focalizzati” nella zona dove insistono i punti, limitando però la possibilità di confronto tra di loro. Infatti, con assi x diversi diventa più complicato confrontare la distribuzione delle auto con 4 cilindri rispetto a quelle con 8. Quindi, quando va usato scales?
Scales risulta molto utile quando si ha a che fare con barplot, vediamone un esempio.
Con il codice base facet_wrap(~ class, nrow = 1), si ottiene il seguente grafico:
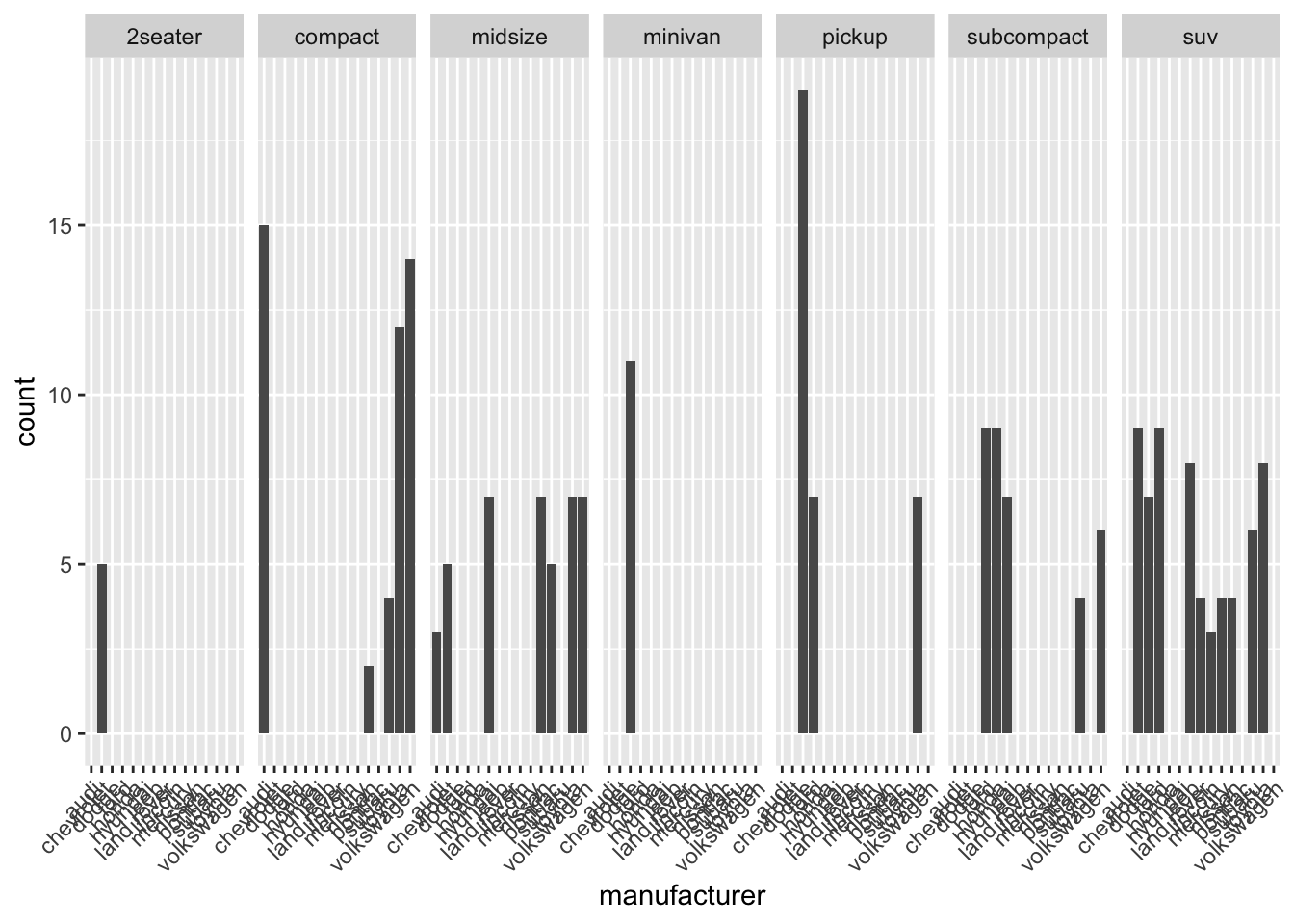
Figura 4: Senza scales
Lo dico io: non si capisce niente| Se notate, ci sono un sacco di case automobilistiche che non hanno auto in certe classi, che lasciano quindi dei vuoti che creano difficoltà nella lettura dei nomi delle case automobilistiche stesse e nella visualizzazione ottimale dei valori.
Per aggiustare questa oscenità, usiamo facet_wrap(~ class, nrow = 1, scales = "free_x"):
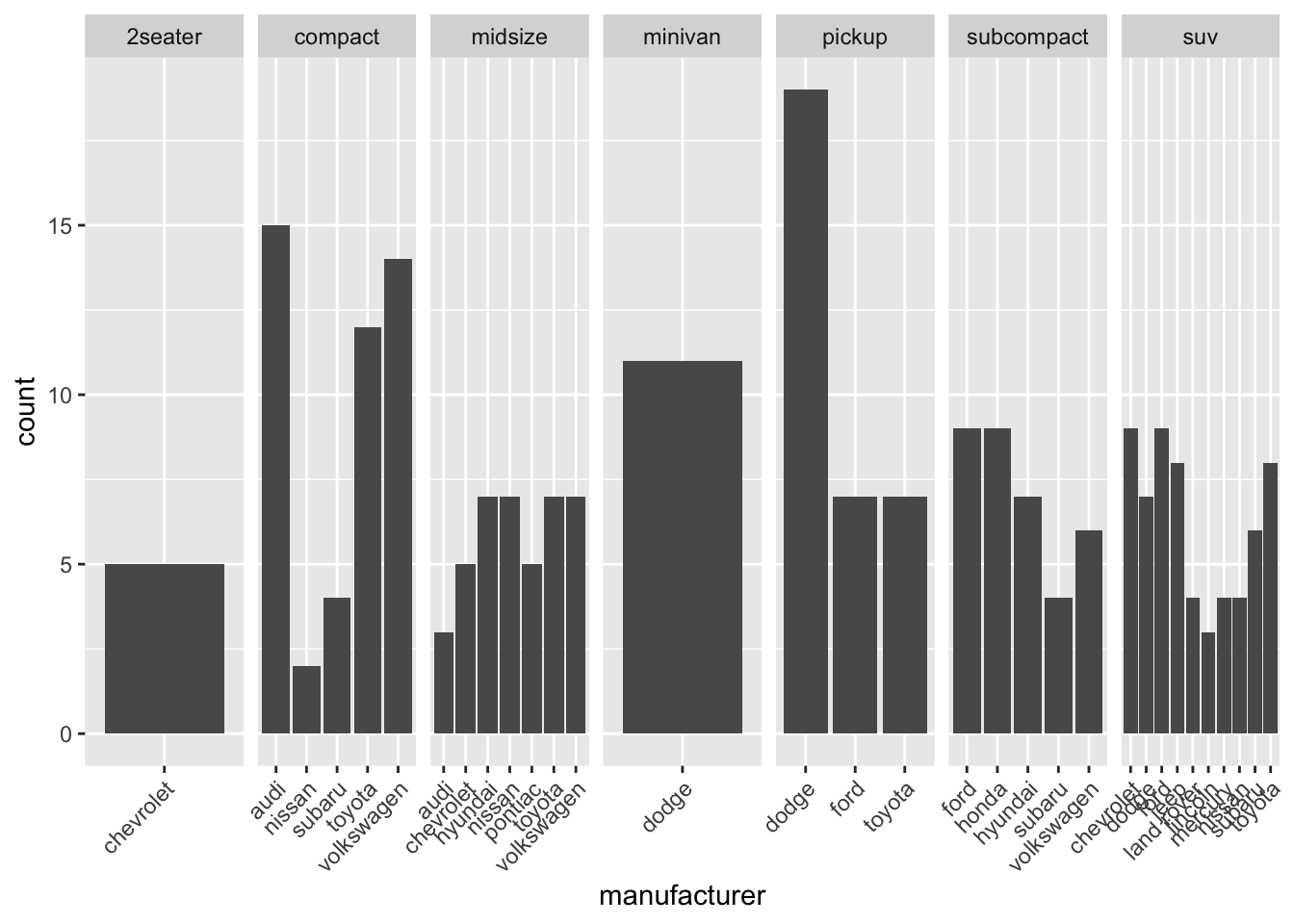
Figura 5: Con scales = “free_x”
Come si vede, ora solo le case automobilistiche con almeno una auto sono rappresentate in ogni classe. Questo rende il grafico sicuramente più chiaro, meno vuoto e più leggibile. Certo, nella classe suv ancora non si riescono a leggere bene i nomi, questo perchè ogni classe occupa lo stesso spazio nel grafico, indipendentemente dal numero di case automobilistiche che contiene.
Qui ci viene in aiuto facet_grid.
Facet_grid
Prima di vedere come migliorare ulteriormente il grafico in figura 5, analizziamo le caratteristiche della funzione facet_grid.
Come detto nell’introduzione, la differenza rispetto alla funzione precedente risiede nella possibilità di creare una griglia di grafici che rappresenta i dati divisi secondo due variabili categoriche (una divisa per colonne e l’altra divisa per righe).
Il comando della funzione base è facet_wrap(categorica_righe ~ categorica_colonne), di seguito un esempio.
ggplot(data = mtcars) +
geom_point(mapping = aes(x = mpg, y = hp), color = "blue") +
facet_grid(am ~ cyl)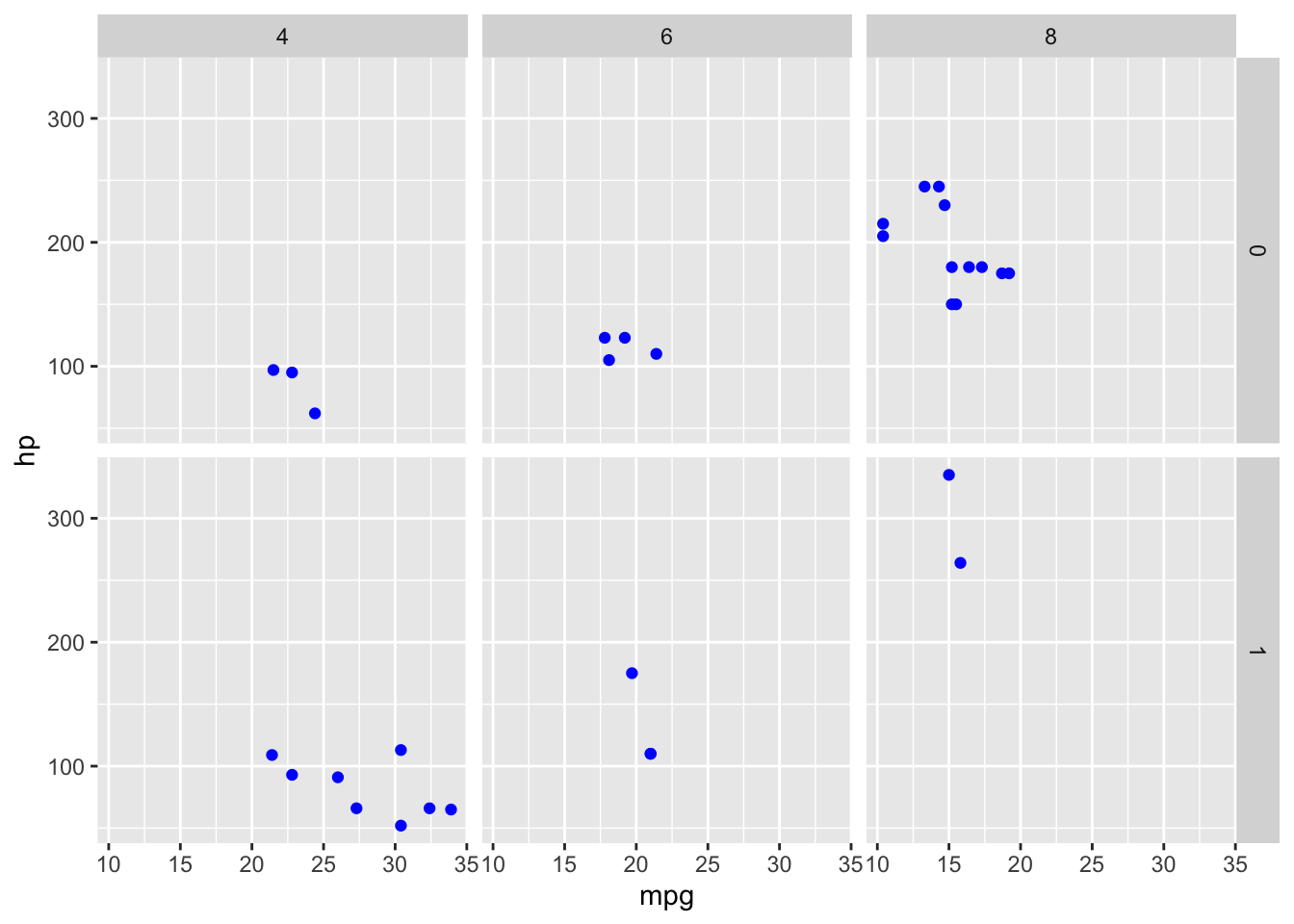
Figura 6: Esempio dell’uso di facet_grid()
Come si può intuire, il numero di righe e di colonne è determinato dal numero di valori di ogni variabile categorica, non si può, dunque, indicare il numero di righe e/o colonne che dovrà avere il grafico.
Quali sono le impostazioni che si possono chiamare?
scales: in modo analogo a quello che fa in facet_wrap, scales ci permette di decidere se avere assi con range comuni per tutti i grafici oppure diversificati in base al range dei dati di ogni grafico
drop: opzione importante se si vogliono eliminare i grafici corrispondenti alle categorie senza alcun dato (grafici vuoti). Le opzioni sono T (elimina) o F (mantieni tutti)switch: sostituisce strip.position della funzione facet_wrap. Le opzioni però sono diverse, infatti va indicato l’asse per cui si vuole cambiare la posizione delle etichette rispetto a quella di default (alto per le x, destra per le y); il alternativa si può indicare “both” per avere un cambio su entrambi gli assi
margins: questa funzione non viene quasi mai citata, ma può risultare utile a volte. Infatti, dà la possibilità di aggiungere dei pannelli in cui sono graficati tutti i dati di ogni riga/colonna o di entrambe. Le opzioni sono TRUE per avere tutti i grafici sommatori, oppure la stringa corrispondente alla variabile categorica di cui vogliamo i grafici sommati
ggplot(data = mtcars) +
geom_point(mapping = aes(x = mpg, y = hp), color = "blue") +
facet_grid(am ~ cyl, margins = "am", switch = "x")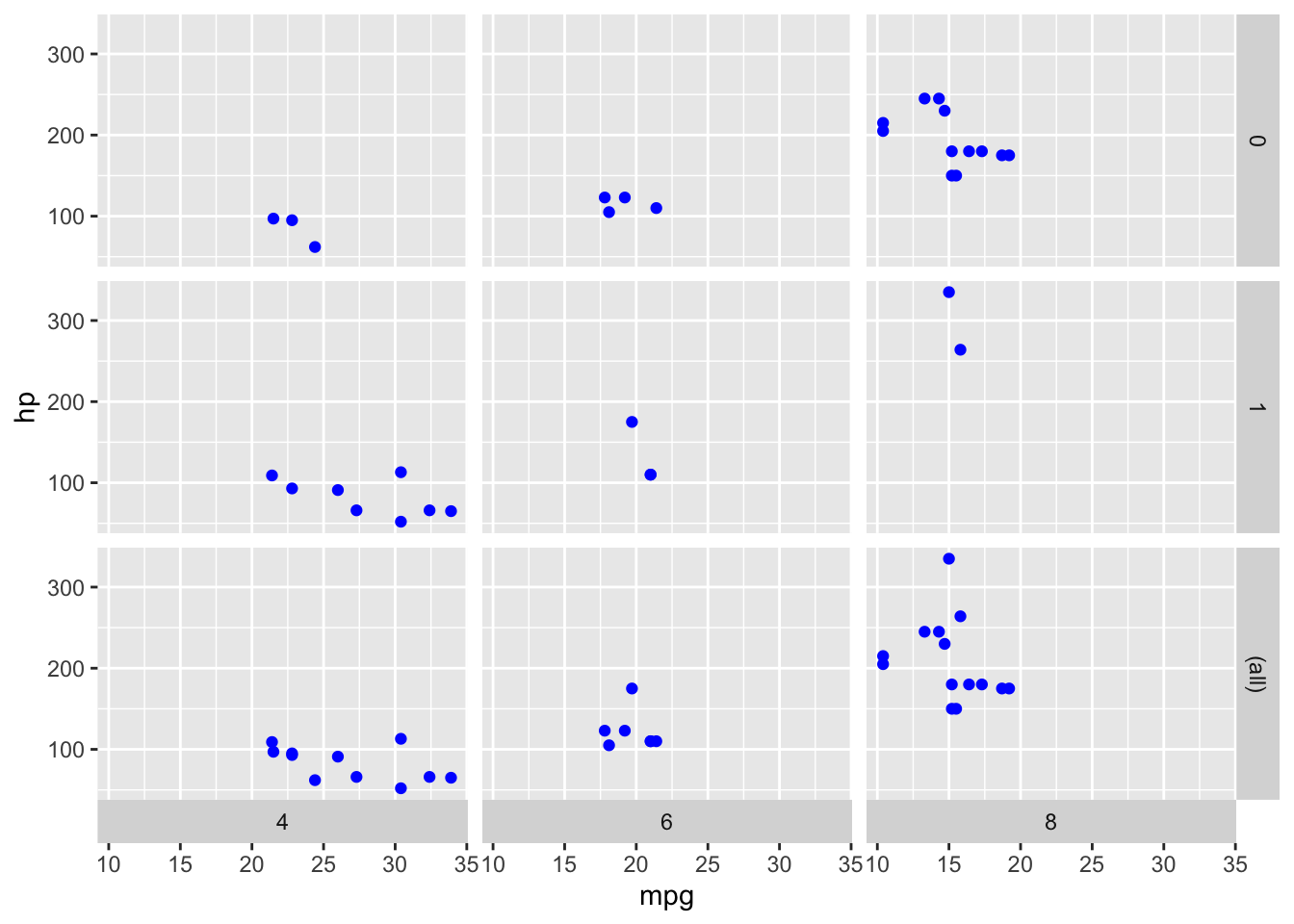
Figura 7: Esempio dell’uso di margins in facet_grid
Ed ecco qui che è comparsa una terza riga, che vede grafici che sono l’unione di quelli sopra.
Torniamo ora all’esempio 2, come possiamo sistemarlo con facet_grid?
Una cosa importante che non ho detto prima, è che facet_grid può prendere come input anche una sola variabile categorica, mentre l’altra sarà rappresentata da un punto (.). In più, c’è un ulteriore input che si può dare alla funzione che non ho citato prima: space.
Space è un po’ come scales, ma al posto che settare i singoli assi, modifica gli assi x e y “generali” del grafico, come se la griglia di grafici avesse un asse x e un asse y propri.
Scendiamo più nel pratico, il problema di prima era che ogni classe occupava lo stesso spazio nel grafico, indipendentemente dal numero di case automobilistiche che conteneva. Quello che fa space è proprio organizzare gli assi “generali” in modo tale che ci sia proporzione tra i vari grafici. Le opzioni possibili sono le stesse di scales: free, free_x/y e fixed.
Vediamo subito come funziona, perchè risulta più facile da visualizzare che spiegare.
ggplot(data = mpg) +
geom_bar(aes(x = manufacturer)) +
facet_grid(. ~ class, scales = "free_x", space = "free_x") +
theme(axis.text.x = element_text(angle = 45, hjust=1))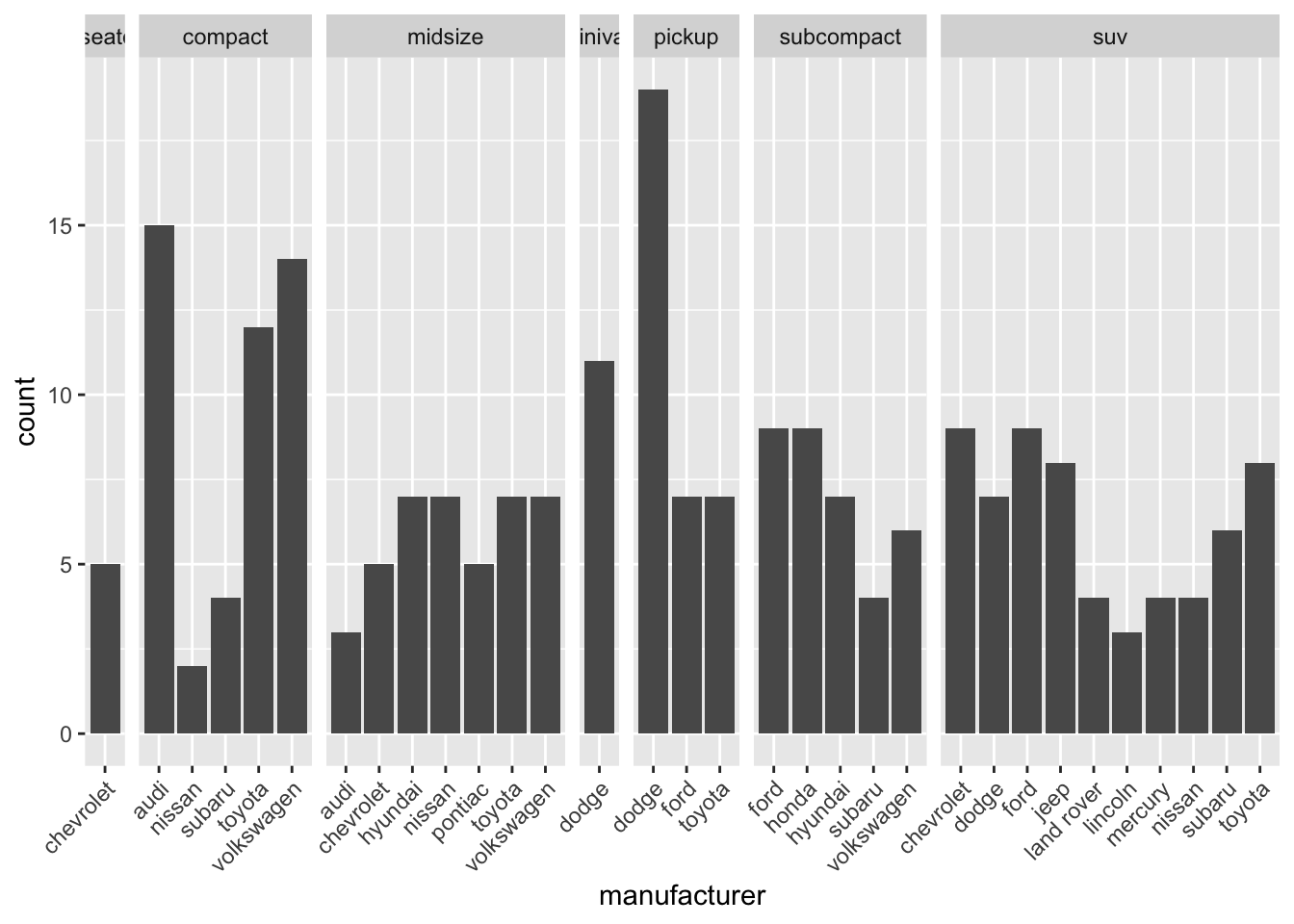
Figura 8: Con scales e space = “free_x”
Il grafico è molto più chiaro ora, purtroppo le classi con poche occorrenze hanno il nome tagliato; ci sono varie opzioni per sistemare ciò:
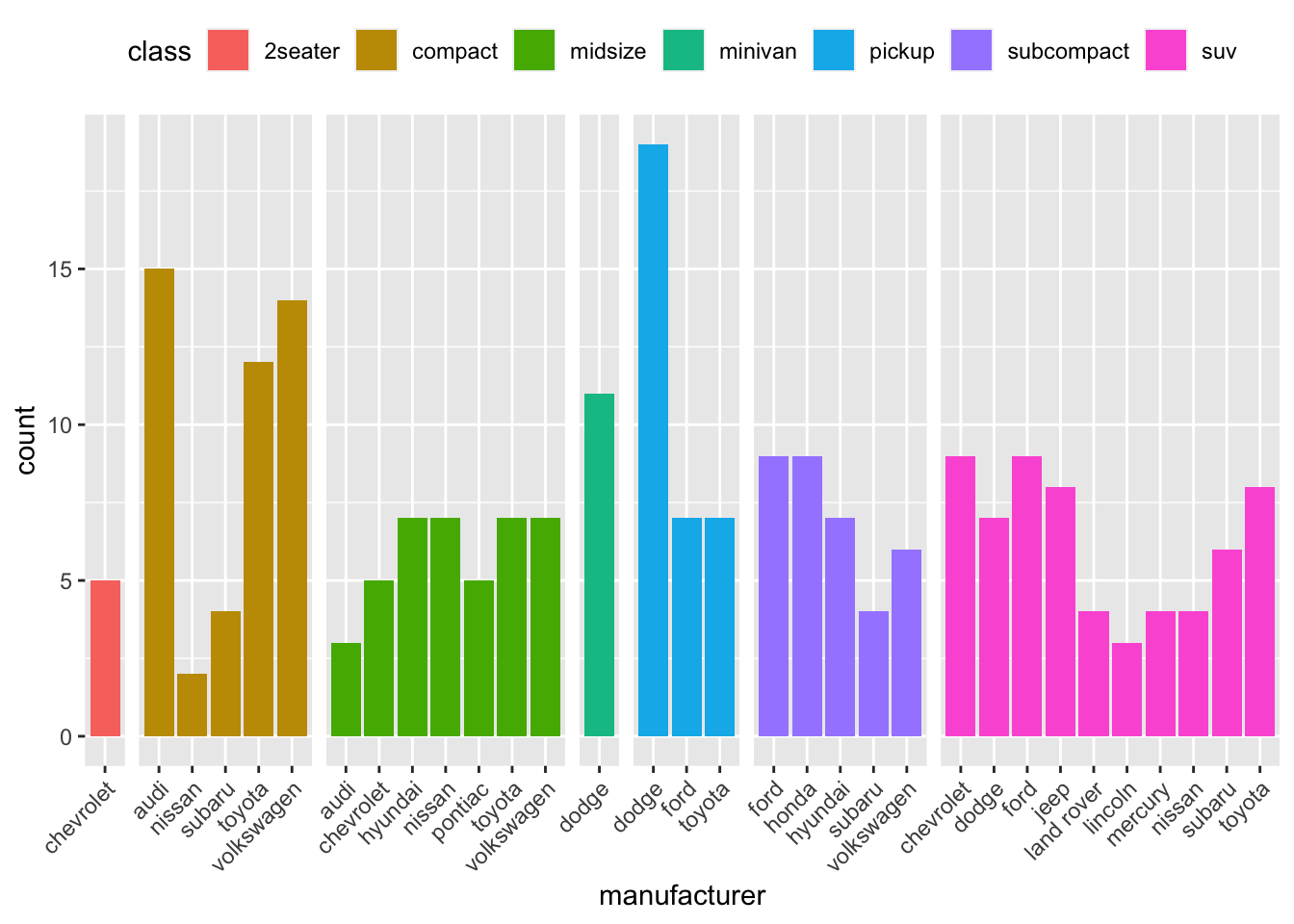
Figura 9: Grafico avanzato che permette di distinguere bene i nomi delle classi
Se notate bene, vedrete nel codice del grafico in figura 8 una aggiunta, ovvero il comando theme. Non abbiamo ancora affrontato questo argomento, ma come immaginerete sarà tema di un futuro post; per il momento vi lascio intuire da soli cosa faccia, suggerendo un suo utilizzo anche per la creazione del grafico in figura 9.
