Molte di queste operazioni possono essere effettuate coi pacchetti base, ma per comodità vi farò vedere alcune funzioni di un pacchetto molto importante: il mondo tidyverse.
Di seguito è mostrato un pezzo del dataset che useremo oggi:
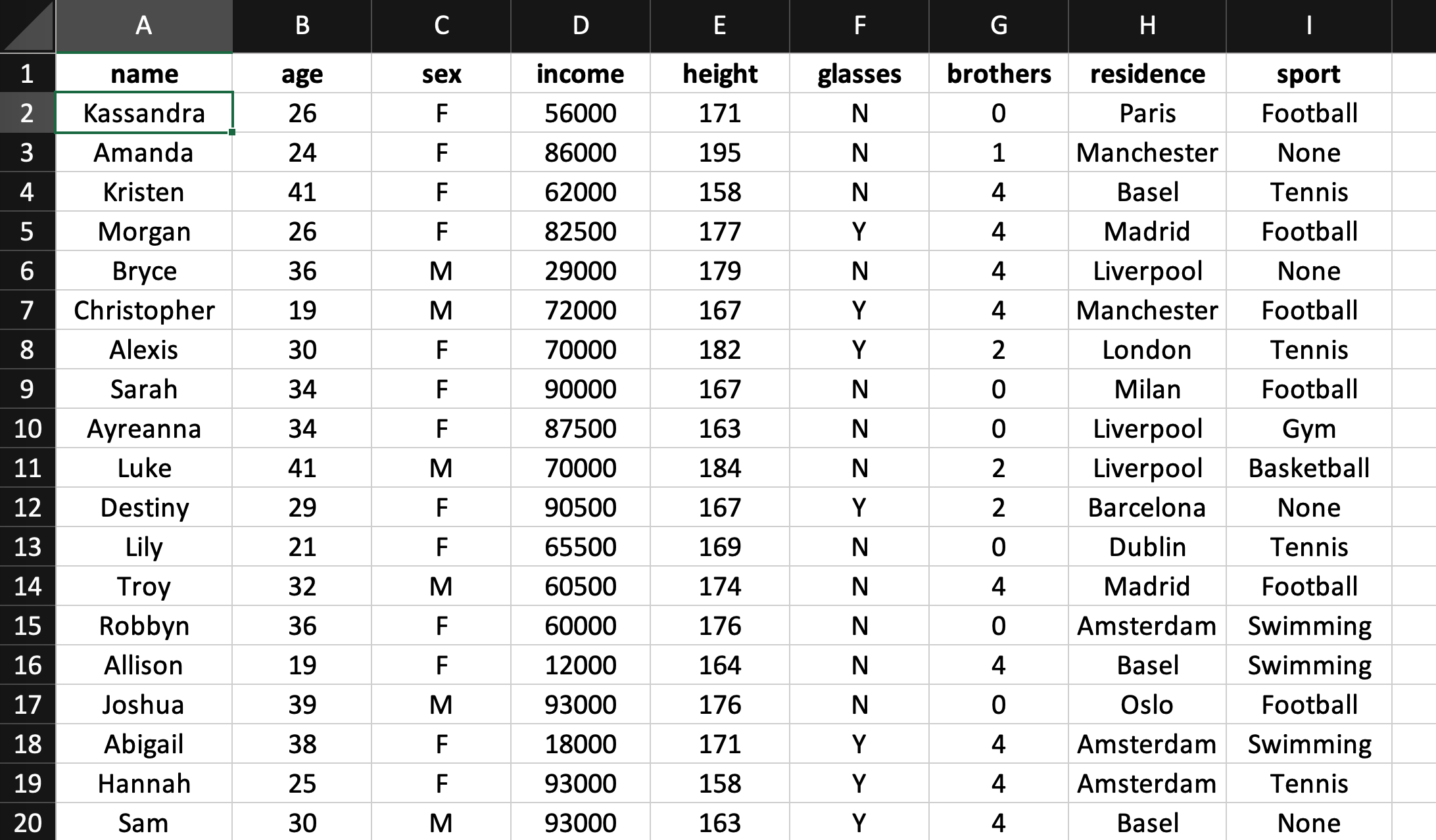
Questa sarà la prima e ultima volta che vedremo un dataset da Excel, ora vediamo come fare tutte le operazioni su R.
Import
Il primo passo è, ovviamente, quello di importare il dataset. La funzione base èread.table (ma ci sono anche le funzioni read.csv e read.delim che fanno la stessa cosa).
Questa funzione ha vari input, vediamo i principali:
Struttura del dataset
Successivamente, bisogna guardare la struttura del dataset. Ci sono varie funzioni da utilizzare, analizziamole.
Dimensioni
La prima cosa da ricavare sono le dimensioni del dataset. Per fare questo c’è la funzione dim:
|
|
[1] 250 9Il risultato è un vettore di due valori, il primo relativo al numero di righe, il secondo a quello delle colonne.
Nomi variabili
Un’altra cosa molto utile, sopratutto in dataset con poche variabili, è ricavare un vettore con i loro nomi.
Ci sono due funzioni che fanno il caso nostro e che forniscono lo stesso identico risultato: colnames e names.
|
|
[1] "name" "age" "sex" "income" "height" "glasses"
[7] "brothers" "residence" "sport" Head
Per vedere il dataset come fosse nella figura 1 su R si usa la funzione head. Questa funzione prende come input il nome del dataset e il numero di righe da printare. Questa funzione è molto utile quando si ha a che fare con dataset di grandi dimensioni, per vedere a grandi linee la sua struttura.
|
|
name age sex income height glasses brothers residence sport
1 Kassandra 26 F 56000 171 N 0 Paris Football
2 Amanda 24 F 86000 195 N 1 Manchester None
3 Kristen 41 F 62000 158 N 4 Basel Tennis
4 Morgan 26 F 82500 177 Y 4 Madrid Football
5 Bryce 36 M 29000 179 N 4 Liverpool None
6 Christopher 19 M 72000 167 Y 4 Manchester Football
7 Alexis 30 F 70000 182 Y 2 London Tennis
8 Sarah 34 F 90000 167 N 0 Milan Football
9 Ayreanna 34 F 87500 163 N 0 Liverpool Gym
10 Luke 41 M 70000 184 N 2 Liverpool BasketballIn questo caso ho deciso di printare le prime 10 righe.
Structure
La funzionestr ci permette di analizzare la struttura del dataset.
|
|
'data.frame': 250 obs. of 9 variables:
$ name : chr "Kassandra" "Amanda" "Kristen" "Morgan" ...
$ age : int 26 24 41 26 36 19 30 34 34 41 ...
$ sex : chr "F" "F" "F" "F" ...
$ income : num 56000 86000 62000 82500 29000 72000 70000 90000 87500 70000 ...
$ height : int 171 195 158 177 179 167 182 167 163 184 ...
$ glasses : chr "N" "N" "N" "Y" ...
$ brothers : int 0 1 4 4 4 4 2 0 0 2 ...
$ residence: chr "Paris" "Manchester" "Basel" "Madrid" ...
$ sport : chr "Football" "None" "Tennis" "Football" ...Come possiamo vedere, questa funzione ci fornisce subito le dimensioni del dataset (andando quindi ad inglobare la funzione dim). Successivamente, fornisce un elenco delle variabili (le colonne) in questa forma:
nome della colonna: tipo di dato primi valori
Summary
Il passo successivo è ricavare delle statistiche di base sulle variabili.
La funzione summary fa il caso nostro: ci fornisce informazioni su quartili, media e range per le variabili numeriche e i count per le variabili categoriche.
|
|
name age sex income
Length:250 Min. :18.00 Length:250 Min. : 10000
Class :character 1st Qu.:23.00 Class :character 1st Qu.: 31125
Mode :character Median :30.00 Mode :character Median : 54500
Mean :30.58 Mean : 54702
3rd Qu.:38.00 3rd Qu.: 76875
Max. :45.00 Max. :100000
NA's :3
height glasses brothers residence
Min. :151.0 Length:250 Min. :0.00 Length:250
1st Qu.:168.0 Class :character 1st Qu.:0.00 Class :character
Median :176.0 Mode :character Median :2.00 Mode :character
Mean :175.4 Mean :2.19
3rd Qu.:182.0 3rd Qu.:4.00
Max. :213.0 Max. :5.00
NA's :3 NA's :2
sport
Length:250
Class :character
Mode :character Come si vede, la funzione fornisce le statistiche per le varie variabili; inoltre, fornisce il numero di NA per ogni variabile.
Ciò che notiamo però è che le variabili sex, residence, sport e glasses sono codificate come characters e non ci viene fornito il numero di counts. Una cosa simile avviene per il numero di fratelli, che R interpreta come variabile numerica continua e ci fornisce le statistiche, quando a noi sarebbe più utile avere i counts.
Modificare le variabili
A questo punto, c’è bisogno di modificare alcune variabili. Vediamo quali sono le modifiche più comuni.
Cambiare type
Come detto poco fa, c’è bisogno che alcune variabili diventino categoriche. La funzione che si può usare per fare ciò è as.factor (o semplicemente factor), e può essere usata singolarmente per ogni variabile da cambiare oppure all’interno della funzione lapply.
Vediamo entrambi gli approcci:
|
|
Factor w/ 2 levels "F","M": 1 1 1 1 2 2 1 1 1 2 ...Vediamo ora come sia stato trasformato in una variabile di tipo factor (il termine usato in R per quello che noi consideriamo categorico). Da notare come ci sia l’operazione di assegnazione (<-), fondamentale affinchè il cambiamento sia memorizzato all’interno del dataset.
Vediamo ora come effettuare i cambiamenti su tutte le variabili in un solo comando. Questo viene fatto tramite la funzionelapply che si struttura in questo modo: lapply(colonne, funzione da applicare). Nel nostro caso sarà:
|
|
'data.frame': 250 obs. of 9 variables:
$ name : chr "Kassandra" "Amanda" "Kristen" "Morgan" ...
$ age : int 26 24 41 26 36 19 30 34 34 41 ...
$ sex : Factor w/ 2 levels "F","M": 1 1 1 1 2 2 1 1 1 2 ...
$ income : num 56000 86000 62000 82500 29000 72000 70000 90000 87500 70000 ...
$ height : int 171 195 158 177 179 167 182 167 163 184 ...
$ glasses : Factor w/ 2 levels "N","Y": 1 1 1 2 1 2 2 1 1 1 ...
$ brothers : Factor w/ 6 levels "0","1","2","3",..: 1 2 5 5 5 5 3 1 1 3 ...
$ residence: Factor w/ 15 levels "Amsterdam","Barcelona",..: 13 9 3 8 6 9 7 10 6 6 ...
$ sport : Factor w/ 8 levels "Athletics","Basketball",..: 4 6 8 4 6 4 8 4 5 2 ...In questo caso ho usato i numeri per indicizzare le colonne, ma avrei potuto anche usare direttamente i nomi stessi delle colonne (il che renderebbe l’operazione più chiara). Il risultato è quello desiderato; anche se ora si nota come la variabile glasses abbia due livelli (“N” e “Y”), ma noi vorremmo avere lo 0 per il “N” e l’1 per il “Y” (codifica standard per variabili booleane).
Relevel
A nostro soccorso arriva la possibilità di fare un cambio dei levels con l’omonima funzione:
|
|
Factor w/ 2 levels "0","1": 1 1 1 2 1 2 2 1 1 1 ...Non ci si deve spaventare se dopo i “:” ci siano l’1 e il 2; quei valori indicano quale è l’indice del livello a cui corrisponde quel valore.
Ora tutte le variabili dovrebbero essere sistemate, vediamo ora se la funzione summary ci fornisce il risultato desiderato:
|
|
name age sex income height
Length:250 Min. :18.00 F :127 Min. : 10000 Min. :151.0
Class :character 1st Qu.:23.00 M :121 1st Qu.: 31125 1st Qu.:168.0
Mode :character Median :30.00 NA's: 2 Median : 54500 Median :176.0
Mean :30.58 Mean : 54702 Mean :175.4
3rd Qu.:38.00 3rd Qu.: 76875 3rd Qu.:182.0
Max. :45.00 Max. :100000 Max. :213.0
NA's :3 NA's :3
glasses brothers residence sport
0 :137 0 :66 Amsterdam :15 Athletics :19
1 :112 1 :45 Barcelona :17 Basketball:33
NA's: 1 2 :25 Basel :23 Dance : 7
3 : 7 Dublin :21 Football :91
4 :98 Lisbona :12 Gym :18
5 : 7 Liverpool :11 None :33
NA's: 2 London :21 Swimming :15
Madrid :23 Tennis :31
Manchester:21 NA's : 3
Milan :10
Munich :15
Oslo :18
Paris :15
Rome :14
Vienna :14
Sì, il risultato è esattamente quello desiderato. Ora sappiamo che ci sono 127 femmine e 121 maschi, che 112 persone portano gli occhiali e che 33 non fanno alcuno sport.
Ora possiamo passare a vedere come riordinare il dataset.
Riordinare il dataset
Ci sono delle volte in cui si vuole riordinare il dataset, spostando colonne, creando colonne, ordinando per dei valori,… Vediamo come fare.
Spostare colonne
Può essere utile spostare delle colonne, per esempio avere tutte le fattoriali prima e le non fattoriali dopo, riordinarle in ordine alfabetico o per proprie necessità. Ecco qui un paio di esempi.
Iniziamo spostando tutte le variabili fattoriali subito dopo la colonna coi nomi delle persone:
|
|
[1] "name" "glasses" "sex" "brothers" "residence" "sport"
[7] "age" "income" "height" Questo metodo utilizza la funzione select, la quale seleziona solo le colonne indicate nell’ordine fornito.
Questo metodo però implica la conoscenza dei nomi di tutte le variabili fattoriali. Un modo per generalizzare il tutto è il seguente:
|
|
- Selezionare la colonna name
- Selezionare le colonne che sono fattoriali tramite un indexing del vettore colnames con un vettore booleano che indica se una colonna è fattoriale o meno
- Selezionare le colonne non fattoriali tramite lo stesso metodo del punto 2, con la differenza dell’esclusione della variabile name in quanto già selezionata al punto 1
Vi lascio qui di seguito il codice per ordinare le colonne in ordine alfabetico:
|
|
Riordinare in base ai valori di una variabile
Spesso si vuole riordinare l’intero dataset in base a valori crescenti o decrescenti di una variabile.
Questa operazione ci è resa semplice dal comando arrange. Dal momento che l’applicazione di questa funzione è molto immediata, vi fornisco un esempio che ha un passaggio successivo
|
|
name glasses sex brothers residence sport age income height
1 Branden 0 M 1 Amsterdam Basketball 43 100000 199
2 Andrew 1 M 4 Barcelona Football 45 100000 179
3 Barbara 1 F 1 Madrid Gym 35 99500 172
4 Samantha 1 F 0 Rome Athletics 37 99500 165
5 Margariete 1 F 0 Vienna Basketball 37 99000 157
6 Kevin 1 M 4 Lisbona Football 43 98000 172Ecco un dataset delle 6 persone che guadagnano di più.
|
|
name
1 Branden
2 Andrew
3 Barbara
4 Samantha
5 Margariete
6 KevinAggiungere una colonna
Infine, vediamo come aggiungere una colonna al nostro dataset.
Il modo più semplice per aggiungere al dataset una colonna fatta da un vettore già costruito è cbind(dataframe, vettore).
Io, invece, vi mostro qualcosa di diverso, ovvero creare una colonna in base a valori di un’altra colonna del dataset.
Per fare ciò usiamo la funzione mutate, che ci permette di creare una nuova variabile eseguendo operazioni su altre variabili:
|
|
name glasses sex brothers residence
Length:250 0 :137 F :127 0 :66 Basel : 23
Class :character 1 :112 M :121 1 :45 Madrid : 23
Mode :character NA's: 1 NA's: 2 2 :25 Dublin : 21
3 : 7 London : 21
4 :98 Manchester: 21
5 : 7 Oslo : 18
NA's: 2 (Other) :123
sport age income height
Football :91 Min. :18.00 Min. : 10000 Min. :151.0
Basketball:33 1st Qu.:23.00 1st Qu.: 31125 1st Qu.:168.0
None :33 Median :30.00 Median : 54500 Median :176.0
Tennis :31 Mean :30.58 Mean : 54702 Mean :175.4
Athletics :19 3rd Qu.:38.00 3rd Qu.: 76875 3rd Qu.:182.0
(Other) :40 Max. :45.00 Max. :100000 Max. :213.0
NA's : 3 NA's :3 NA's :3
plusincome
0:127
1:123
Vediamo come ci siano 127 persone che hanno un income minore della media e 123 che lo hanno superiore.
Conclusioni
Mi auguro che questo post introduttivo all’analisi di un dataset, in particolare di un nuovo dataset, sia stato utile. Ci sono concetti basilari che prevedono anche l’utilizzo di codici più strutturati. Il mio consiglio è, come sempre, provare, provare e riprovare (quasi “giocare”) con i dataset e R: è il modo migliore per imparare e familiarizzare con questo linguaggio.
